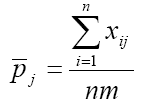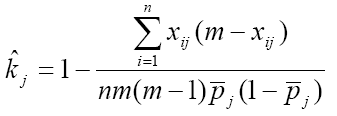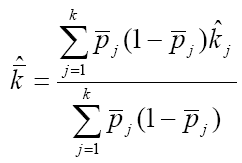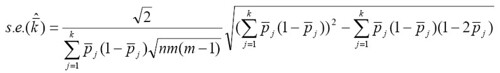SAS 裡面有相當多語法,後面是要接一連串的變數,如 KEEP, RENAME,ARRAY 或 PROC FREQ 程序中的 TABLES 指令等等。在遇到具有數十個甚至數百個變數的資料庫時,有極大的機會需要輸入大量變數在這些語法中。如果這些變數在一開始設定時已經有一些規則可循,比方說有共同的開頭字母(prefix),如 VAR001,VAR002,VAR003....,那就可以用一些連字符號 (-) 來節省輸入時間。但如果這些變數名稱沒有規則可循,這就會變成一個相當頭痛的問題。Robert J. Morris 在 2005 年的 SUGI 30 上發表了一篇專門處理龐大變數的文章,並寫了幾個text utility macro 供大家使用。
在本文中,只用一個含有六個變數的資料來當範例,但實際上可以想像中上百個甚至上千個變數。 Robert 用幾個例子來介紹 text utility macro 的用法。在這三個例子所出現的程式中有一個共同點,都是要先設定下面這行程式來表示:
%let orig_vars = a01a a01b d01 d02 t1_r t2_r;
EXAMPLE 1 – RECODING VARIABLES
假設這六個變數是一些數值變數,而我們想要製造另外六個新的變數,當舊變數是正時,新變數就是 1 ,反之則是 0。此外,新變數的名稱,是在舊變數名稱前加上「r_」。一般直覺上會寫出下面這樣的程式:
data newdata;
set mydata;
array orig[*] &orig_vars;
array recode[*] r_a01a r_a01b r_d01 r_d02 r_t1_r r_t2_r;
do i=1 to dim(orig);
if (orig[i] > 0) then recode[i] = 1; else recode[i] = 0;
end;
run;
這個程式有很大的缺點,那就是當你有上百個變數時,第二個陣列 recode 後面不就要一個一個變數加上 r_ 的開頭。這樣貼上的動作要重複上百次,非常消耗時間。如果使用 Robert 的 text utility macro,程式會變成:
data newdata;
set mydata;
array orig[*] &orig_vars;
array recode[*] %add_string(&orig_vars, r_, location=prefix);
do i=1 to dim(orig);
if (orig[i] > 0) then recode[i] = 1; else recode[i] = 0;
end;
run;
唯一和原始程式不同的地方只是把 recode 陣列後面所引入的參數換成 %add_string 這個 macro。這個 macro 會把 orig_vars 所預設的所有變數一次丟入,然後便會在每個變數前面加上 r_ 的檔頭。這樣 rename 的功能就完成了。
EXAMPLE 2 – PROC MEANS OUTPUT DATA SET
在使用 PROC MEANS 來計算每個變數的一些基本統計量時,有時候會需要將得到的結果另存成一個新的資料集,讓後續的程式能夠繼續使用。在另存的過程中,不免需要將每個變數所得到的各種統計量重新命名,於是含有大量變數的資料庫又會出現如例一的問題。當然,PROC MEANS 的 OUTPUT 語法中有一個叫做 autoname 的 option,可以自動幫你命名,可是當你不滿意 SAS 幫你命的名稱時,就是 %add_string 上場的時候了。
原始程式如下:
proc means data=mydata noprint;
output out=newdata
mean(&orig_vars) = a01a_mean a01b_mean d01_mean
d02_mean t1_r_mean t2_r_mean
max(&orig_vars) = a01a_max a01b_max d01_max
d02_max t1_r_max t2_r_max;
run;
上述程式只是將每個變數的平均數和最大值另存,這樣就要多輸入 2X6=12 個新名字。如果有一百個變數,要另存每個變數的平均數、標準差、最大值、最小值、中位數,那就等於要輸入 5X100=500 個新變數名稱,的確相當煩人。如果使用 %add_string,就會大幅縮減輸入時間:
proc means data=mydata noprint;
output out=newdata
mean(&orig_vars) = %add_string(&orig_vars, _mean)
max(&orig_vars) = %add_string(&orig_vars, _max);
run;
這個 macro 讓每個舊變數的平均數後面都加上 _mean,每個最大值後面都加上 _max。事實上,如果使用 autoname 就可以產生同樣的結果,但難保在實際應用中,不會出現其他想要設定的名稱格式。因此,%add_string 的確有他存在的必要。
EXAMPLE 3 – RENAMING VARIABLES TO HAVE A COMMON PREFIX
當要在 Data step 中大量重新命名變數時,所造成的困擾就相當清楚了。Robert 提供了另一個叫做 %rename_string 的 macro 來解決這個問題。原始程式如下:
data newdata;
set mydata;
rename a01a=r_a01a a01b=r_a01b d01=r_d01 d02=r_d02 t1_r=r_t1_r t2_r=r_t2_r;
run;
如果變數變成一百個,新的變數名稱是 r_ 加上舊的變數名稱,大概 ctrl+v 會按不完。用 %rename_string 輕鬆搞定:
data newdata;
set mydata;
rename %rename_string(&orig_vars, r_, location=prefix);
run;
原本可能要花十幾分鐘的重複貼上時間,現在只要二十秒就可完成批次改變數名稱的動作。
EXAMPLE 4 – PROC FREQ TABLE STATEMENT
在 PROC FREQ 程序中,如果要產生不同變數排列組合的次數分配表,那就是如下所示:
proc freq data=newdata;
tables a01a*r_a01a a01b*r_a01b d01*r_d01 d02*r_d02 t1_r*r_t1_r t2_r*r_t2_r;
run;
上述程式只是簡單的做出每個舊的變數和其對應的新變數(開頭加上 r_ 的那幾個)的次數分配表。我們可以一次使用 %parallel_join 和 %add_string 這兩個 macro 來完成這個動作:
proc freq data=newdata;
tables %parallel_join(
&orig_vars,
%add_string(&orig_vars, r_, location=prefix),
*
);
run;
%parallel_join 可以將 orig_vars 中每一個變數對應到相對位置的另一群變數,而這另一群變數就是由 %add_string 所製造出來(讓每個舊變數前面加上 r_),最後,用「*」把他們分別黏起來,就完成了原始程式碼中 tables 後面那一串文字的輸入了。
EXAMPLE 5 – RENAMING VARIABLES TO HAVE A COUNTER SUFFIX
最後一個例子算是終極大絕招。如果變數名稱太長,用 %rename_string 只會讓變數更長。理想的新變數是像 qvar1、qvar2、qvar3.... 這樣。這次 Robert 一次用三個 text utility macro 來完成這個動作。原始沒有用 macro 的程式碼如下:
data newdata;
set mydata;
rename a01a=qvar1 a01b=qvar2 d01=qvar3 d02=qvar4 t1_r=qvar5 t2_r=qvar6;
run;
新的程式碼看起來比舊的程式碼要來的長,不過一旦變數變成超級多時,新的程式碼看起來就相當短了:
data newdata;
set mydata;
rename %parallel_join(
&orig_vars,
%suffix_counter(qvar, %num_tokens(&orig_vars)),
=
);
run;
在新的程式碼中,一開始也是先引入 %parallel_join 把新舊變數用等號連結起來。在設定新變數名稱時,使用 %suffix_counter 來把新變數設定成 qvar 開頭,而 qvar 後面接著的數字,就由 %num_tokens 來計算 &orig_vars 所設定的每個舊變數的次序。第一個舊變數就會在 qvar 後面加上 1,第二個就加上 2,以此類推。如此一來又大功告成了!!!
原文中還有對每個 text utility macro 做更進一步的參數解說,可從原文載點下載來看。在此僅列出所有 macro 的程式碼,有興趣的人可以自由下載回去使用。
[num_tokens]
%macro num_tokens(words, delim=%str( ));
%local counter;
%* Loop through the words list, incrementing a counter for each word found. ;
%let counter = 1;
%do %while (%length(%scan(&words, &counter, &delim)) > 0);
%let counter = %eval(&counter + 1);
%end;
%* Our loop above pushes the counter past the number of words by 1. ;
%let counter = %eval(&counter - 1);
%* Output the count of the number of words. ;
&counter
%mend num_tokens;
[add_string]
%macro add_string(words, str, delim=%str( ), location=suffix);
%local outstr i word num_words;
%* Verify macro arguments. ;
%if (%length(&words) eq 0) %then %do;
%put ***ERROR(add_string): Required argument 'words' is missing.;
%goto exit;
%end;
%if (%length(&str) eq 0) %then %do;
%put ***ERROR(add_string): Required argument 'str' is missing.;
%goto exit;
%end;
%if (%upcase(&location) ne SUFFIX and %upcase(&location) ne PREFIX) %then %do;
%put ***ERROR(add_string): Optional argument 'location' must be;
%put *** set to SUFFIX or PREFIX.;
%goto exit;
%end;
%* Build the outstr by looping through the words list and adding the
* requested string onto each word. ;
%let outstr = ;
%let num_words = %num_tokens(&words, delim=&delim);
%do i=1 %to &num_words;
%let word = %scan(&words, &i, &delim);
%if (&i eq 1) %then %do;
%if (%upcase(&location) eq PREFIX) %then %do;
%let outstr = &str&word;
%end;
%else %do;
%let outstr = &word&str;
%end;
%end;
%else %do;
%if (%upcase(&location) eq PREFIX) %then %do;
%let outstr = &outstr&delim&str&word;
%end;
%else %do;
%let outstr = &outstr&delim&word&str;
%end;
%end;
%end;
%* Output the new list of words. ;
&outstr
%exit:
%mend add_string;
[rename_string]
%macro rename_string(words, str, delim=%str( ), location=suffix);
%* Verify macro arguments. ;
%if (%length(&words) eq 0) %then %do;
%put ***ERROR(rename_string): Required argument 'words' is missing.;
%goto exit;
%end;
%if (%length(&str) eq 0) %then %do;
%put ***ERROR(rename_string): Required argument 'str' is missing.;
%goto exit;
%end;
%if (%upcase(&location) ne SUFFIX and %upcase(&location) ne PREFIX) %then %do;
%put ***ERROR(rename_string): Optional argument 'location' must be;
%put *** set to SUFFIX or PREFIX.;
%goto exit;
%end;
%* Since rename_string is just a special case of parallel_join,
* simply pass the appropriate arguments on to that macro. ;
%parallel_join(
&words,
%add_string(&words, &str, delim=&delim, location=&location),
=,
delim1 = &delim,
delim2 = &delim
)
%exit:
%mend rename_string;
[suffix_counter]
%macro suffix_counter(base, end, start=1, zpad=0);
%local outstr i counter;
%* Verify macro arguments. ;
%if (%length(&base) eq 0) %then %do;
%put ***ERROR(suffix_counter): Required argument 'base' is missing.;
%goto exit;
%end;
%if (%length(&end) eq 0) %then %do;
%put ***ERROR(suffix_counter): Required argument 'end' is missing.;
%goto exit;
%end;
%if (&end < &start) %then %do; %put ***ERROR(suffix_counter): The 'end' argument must not be less; %put *** than the 'start' argument.; %goto exit; %end; %* Construct the outstr by looping from &start to &end, adding the counter * value to &base in each iteration. To handle the zero-padding, use the * putn function to format the counter variable with the Z. format. ; %let outstr=; %do i=&start %to &end; %if (&zpad > 0) %then %do;
%let counter = %sysfunc(putn(&i, z&zpad..));
%end;
%else %do;
%let counter = &i;
%end;
%let outstr=&outstr &base&counter;
%end;
%* Output the new list. ;
&outstr
%exit:
%mend suffix_counter;
[parallel_join]
%macro parallel_join(words1, words2, joinstr, delim1=%str( ), delim2=%str( ));
%local i num_words1 num_words2 word outstr;
%* Verify macro arguments. ;
%if (%length(&words1) eq 0) %then %do;
%put ***ERROR(parallel_join): Required argument 'words1' is missing.;
%goto exit;
%end;
%if (%length(&words2) eq 0) %then %do;
%put ***ERROR(parallel_join): Required argument 'words2' is missing.;
%goto exit;
%end;
%if (%length(&joinstr) eq 0) %then %do;
%put ***ERROR(parallel_join): Required argument 'joinstr' is missing.;
%goto exit;
%end;
%* Find the number of words in each list. ;
%let num_words1 = %num_tokens(&words1, delim=&delim1);
%let num_words2 = %num_tokens(&words2, delim=&delim2);
%* Check the number of words. ;
%if (&num_words1 ne &num_words2) %then %do;
%put ***ERROR(parallel_join): The number of words in 'words1' and;
%put *** 'words2' must be equal.;
%goto exit;
%end;
%* Build the outstr by looping through the corresponding words and joining
* them by the joinstr. ;
%let outstr=;
%do i = 1 %to &num_words1;
%let word = %scan(&words1, &i, &delim1);
%let outstr = &outstr &word&joinstr%scan(&words2, &i, &delim2);
%end;
%* Output the list of joined words. ;
&outstr
%exit:
%mend parallel_join;
CONTACT INFORMATION
The author welcomes any comments, questions, or suggestions for improvements. Contact the author at:
Robert J. (Joey) Morris
RTI International
3040 Cornwallis Rd.
Research Triangle Park, NC 27709
Email: rjmorris@rti.org