這一篇 SUGI 技術文件是我個人認為本年度最重要的發表之一。Mixed model 在九零年代初期才正式被 SAS 納入為正規的 procedure 語法裡面(也就是 proc mixed)。在此之前,想要配適 mixed model 的人只能用一些已經發表出來的 macro 程式下去跑,極為不方便。可是,縱使有 proc mixed 的出現,還是不能解決大多數人所遇到的問題,那就是 mixed model 配適過程中進行模式選取的複雜性。University of Nevada- Reno 統計系教授 George Fernandez 在多年前就開始進行簡化 mixed model 模式選取複雜性的技術研究,並不斷改良他的程式發表在每一年度的 SUGI 上。今年在 SAS Global Forum 2007 年會上,他終於發佈了一個「終極完整版」的簡化程式(以下簡稱 ALLMIXED2)。使用者可以在一個固定的介面底下輸入少量指令,然後讓 SAS 自動進行 pre-screen、model selection 和 model diagnostic 的動作。
這份技術文件長達二十頁,可是並沒有詳細提到 ALLMIXED2 的使用方法,反而著重在 IC(information criteria)在模式選取上所扮演的角色。但基本上我們都知道,無論是使用哪一種 IC(AIC、AICC、BIC and so on...),越小的 IC 值表示該模式越好。雖然這個判定方法有一些缺點(嚴謹一點的人則愛用 LRT(Likelihood Ratio Test)),但這仍舊是一個相當重要的指標。至於真正 ALLMIXED2 的使用方法,則是放在 George Fernandez 的網站裡面。
ALLMIXED2 有下列一些特點:
- 可以吃各種不同格式的資料(SAS data files, EXCEL, Access, txt)
- 可以一次輸入兩個以上的 Y(反應變數),讓程式可以同時去配適不同的模式。
- 針對可能含有大量變數的資料,可以先執行 pre-screen 流程讓 GLMSELECT 把一些不重要的變數挑掉。若變數不多,則可以跳掉這個步驟。
- 可找出使模式最佳的 covariance structure。
- 可以強迫某些變數一定要放在模式中而不被刪除,無論這些變數是否顯著。
- 可以對變數進行線性(linear)、二次項(quadratic)和交互作用項(interaction)的檢定。另外,還可檢定模式是否具有多重共線性(multicollinearity)。
- 可以進行模式診斷以檢測是否具有離群值。
- 可將結果存成 Word, HTML 和 PDF 檔格式。SAS log 和 error 訊息也可另存新檔。
- 無法進行變數三次項(cubic)的檢定
- 無法進行 linear spline mixed model 的模式配適。
- 無法使用 estimate 和 contrast 指令。
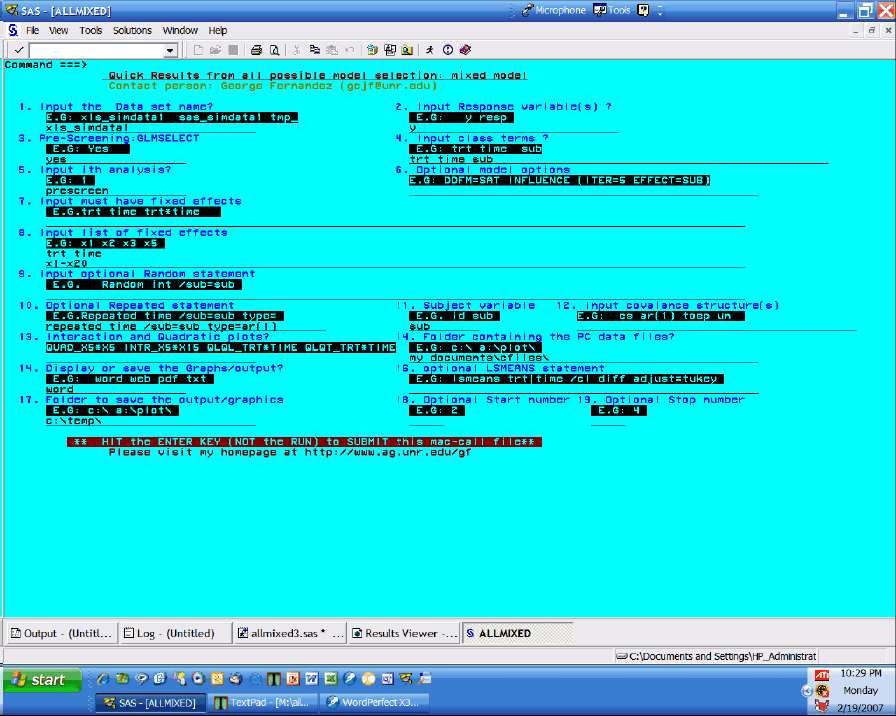
ALLMIXED2 和詳細的使用步驟解說(共計有五大步驟)都放在 Georage Fernandez 的網站上:http://www.ag.unr.edu/gf。但說實在的,他的網頁版面設計的很亂(如下所示)。
想要找到載點,請先點右邊頁框中有隻跑來跑去的灰色小狗。然後會出現一段宣告:
Quick Results from Data analysis Demo Agreement
By clicking the "Accept" button you are agreeing to the following :
THE INFORMATION, CODE AND EXECUTABLES PROVIDED ARE PROVIDED AS IS WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. IN NO EVENT SHALL George Fernandez BE LIABLE FOR ANY DAMAGES WHATSOEVER INCLUDING DIRECT, INDIRECT, INCIDENTAL, CONSEQUENTIAL, LOSS OF BUSINESS PROFITS OR SPECIAL DAMAGES, EVEN IF George Fernandez HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
點選「Accept」後,會要求你填寫個人基本資料。填完後按「Submit Comments」,就可以下載程式和說明使用手冊了。
接著,讓我先來介紹整個 ALLMIXED2 介面的內容。
- Input the Data set name? -- 輸入資料檔案名稱。特別要注意的是,副檔名必須寫在前面,以供程式知道資料檔案名稱格式。例如,檔案名稱是 SIMDATA1.sd7sas,則欄位內必須填寫 SAS_SIMDATA1。目前可供使用的資料檔案格式為 xls, tab, txt, mdb, SAS, TMP。
- Input Response variable(s)? -- 輸入反應變數。特別注意,這邊可以輸入多個反應變數,因為 ALLMIXED2 可以一次配適兩個以上的 mixed model。
- Pre-Screening: GLMSELECT -- 這個欄位是專門做獨立變數 X 預選的工作。如果你有超過二十個以上的獨立變數,ALLMIXED2 會啟動 PROC GLMSELECT 程序挑掉一些不重要的,差不多會留下最後十個比較重要的變數。輸入 yes 就會啟動。留著空白就不會啟動。
- Input class terms? -- 輸入離散型的變數。
- Input ith analysis? -- 你可以輸入任何數值或文字給你分析結果的輸出檔案加上註解。基本上填什麼都不會影響到分析結果。
- Optional model options -- 可以在任意在 model statement 後面加上各種 option。比方說若要進行模式診斷,則可以寫上 DDFM=SAT INFLUENCE (ITER=5 EFFECT=SUB)。由於這是選擇性欄位,所以留著空白也可以。
- Input must have fixed effects -- 根據不同研究的需要,有些變數是無論是否顯著都一定要放進模式裡面。如果有這些變數存在,那就需要將這些變數填入這個欄位裡面,否則可能會在模式選取的階段被挑掉。
- Input list of fixed effects -- 這個欄位就可以放進任何固定效果因子。ALLMIXED2 會針對這些因子做篩選的工作。共計兩行的空白欄位,可以輸入很多固定效果因子。
- Input optional Random statement -- 如果有隨機效果因子,則 random statement 的語法必須完整地填入這個空白欄位。如 random int / sub=sub。
- Optional Repeated statement -- 和欄位九一樣,如果需要輸入 repeated statement,就需要在這個欄位填入相關的程式,例如: repeated time / sub=sub type=ar(1)。
- Subject variable -- 填入 subject 變數的地方。
- Input covariance structure(s) -- 填入 covariance structure 的地方。這邊可以填入數個 covariance structure,程式會自動幫使用者挑出最好的 covariance structure。
- Interaction and quadratic plots? -- 可以繪製交互作用項以及二次項 vs 反應變數的圖形,並且分析是否顯著。
- Folder containing the PC data files -- 這是讓使用者指定原始資料檔案所放置的路徑位置。
- Display or save the Graphs/output? -- 可以讓使用者指定要存出報表的格式。目前可輸出的格式有 word, web, pdf 和 txt。
- optional LSMEANS statement -- 這是可以算 least square means 的欄位,但個人覺得相當無用。
- Folder to save the output/graphics -- 可讓使用者指定想要儲存輸出報表和圖檔的路徑位置。
- Optional Start number -- 在做模式選取時,開始篩選變數的起始值。如果輸入 2,則程式會從只包含兩個獨立變數的模式開始做模式選取。
- Optional stop number -- 在做模式選取時,結束篩選變數的終止時。如果輸入 5,則程式會進行模式選取值到最多只有五個獨立變數在模式。
Step 1: Variable Pre-screen Using SAS GLMSELECT
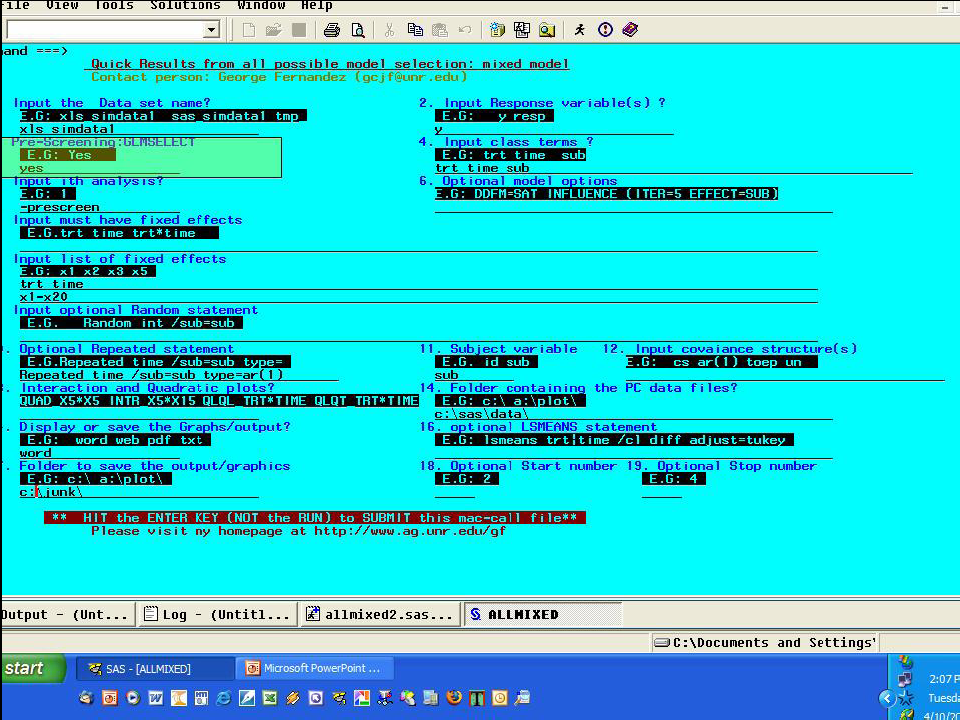
步驟一主要是在進行獨立變數預先篩選的動作。如果資料內並沒有很多變數,則此步驟可以跳過。此外,由於這個步驟需要使用 PROC GLMSELECT 程序。目前的 SAS V9.1 版並沒有這個程式可供執行,所以必須到 SAS 官網下載外掛程式安裝。
- Input the Data set name? -- 由於使用 EXCEL 資料格式,所以填入 xls_simdata1
- Input Response variable(s)? -- 輸入 y
- Pre-Screening: GLMSELECT -- 輸入 yes
- Input class terms? -- 輸入 trt time sub
- Input ith analysis? -- 輸入-prescreen
- Optional model options -- 本階段不需要,所以空白
- Input must have fixed effects -- 本階段不需要,所以空白
- Input list of fixed effects -- 把所有獨立變數放入,輸入 trt time x1-x20
- Input optional Random statement -- 本階段不需要,所以空白
- Optional Repeated statement -- 輸入 repeated time/sub=sub type=ar(1)
- Subject variable -- 輸入 sub
- Input covariance structure(s) -- 本階段不需要,所以空白
- Interaction and quadratic plots? -- 本階段不需要,所以空白
- Folder containing the PC data files -- 輸入 c:\sas\data\ (註:最後一個"\"不能漏掉)
- Display or save the Graphs/output? -- 輸入 word 表示要存成 word 檔
- optional LSMEANS statement -- 本階段不需要,所以空白
- Folder to save the output/graphics -- 輸入 c:\junk\(註:最後一個"\"不能漏掉)
- Optional Start number -- 本階段不需要,所以空白
- Optional stop number -- 本階段不需要,所以空白
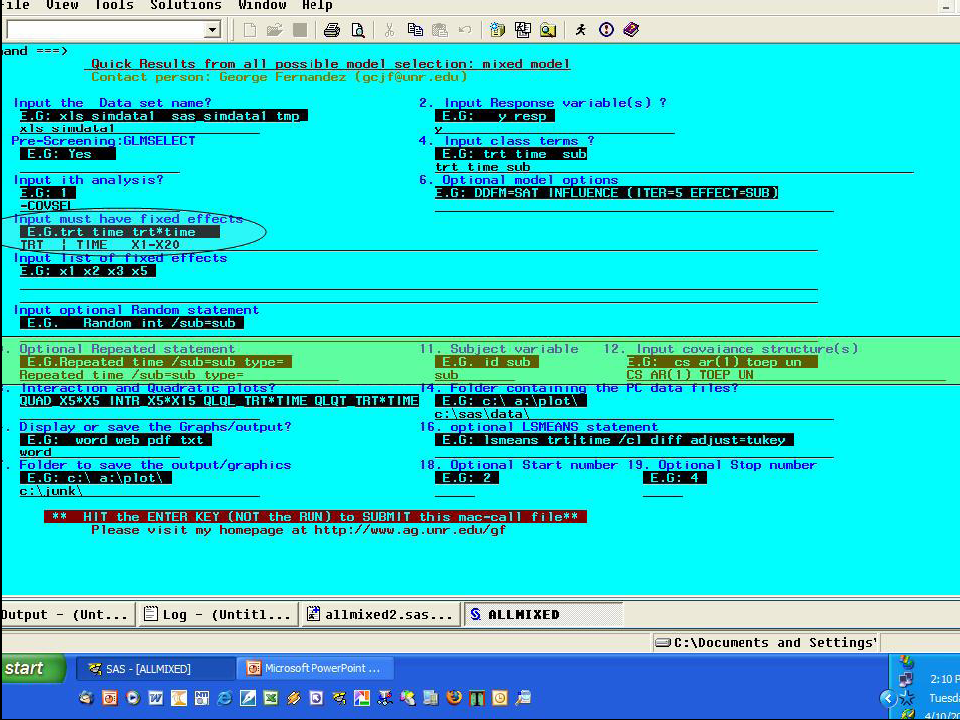
步驟二是要找出最佳的 covariance structure。
- Input the Data set name? -- 輸入 xls_simdata1
- Input Response variable(s)? -- 輸入 y
- Pre-Screening: GLMSELECT -- 本階段不需要,所以空白
- Input class terms? -- 輸入 trt time sub
- Input ith analysis? -- 輸入 -COVSEL
- Optional model options -- 本階段不需要,所以空白
- Input must have fixed effects -- 輸入 trt|time x1-x20
- Input list of fixed effects -- 本階段不需要,所以空白
- Input optional Random statement -- 本階段不需要,所以空白
- Optional Repeated statement -- 輸入 repeated time/sub=sub type= (註:type=後面一定要空白)
- Subject variable -- 輸入 sub
- Input covariance structure(s) -- 輸入所有想要挑選的 covariance structure: cs ar(1) toep un
- Interaction and quadratic plots? -- 本階段不需要,所以空白
- Folder containing the PC data files -- 輸入 c:\sas\data\
- Display or save the Graphs/output? -- 輸入 word 表示要存成 word 檔
- optional LSMEANS statement -- 本階段不需要,所以空白
- Folder to save the output/graphics -- 輸入 c:\junk\
- Optional Start number -- 本階段不需要,所以空白
- Optional stop number -- 本階段不需要,所以空白
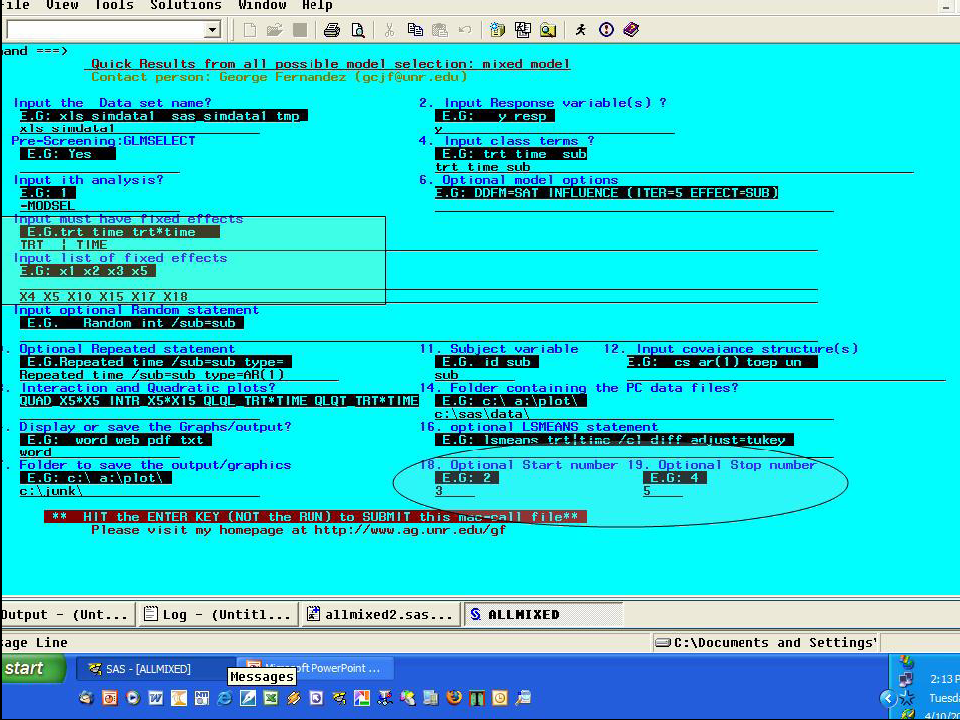
步驟三是在步驟二決定了最佳的 covariance structure(ar(1))之後,開始進行模式選取的動作以找出 the best model。
- Input the Data set name? -- 輸入 xls_simdata1
- Input Response variable(s)? -- 輸入 y
- Pre-Screening: GLMSELECT -- 本階段不需要,所以空白
- Input class terms? -- 輸入 trt time sub
- Input ith analysis? -- 輸入 -MODSEL
- Optional model options -- 本階段不需要,所以空白
- Input must have fixed effects -- 輸入 trt|time,因為這是強制他們進入模式
- Input list of fixed effects -- 輸入步驟一挑出來的變數 x4 x5 x10 x15 x17 x18
- Input optional Random statement -- 本階段不需要,所以空白
- Optional Repeated statement -- 輸入 repeated time/sub=sub type=ar(1)
- Subject variable -- 輸入 sub
- Input covariance structure(s) -- 本階段不需要,所以空白
- Interaction and quadratic plots? -- 本階段不需要,所以空白
- Folder containing the PC data files -- 輸入 c:\sas\data\
- Display or save the Graphs/output? -- 輸入 word
- optional LSMEANS statement -- 本階段不需要,所以空白
- Folder to save the output/graphics -- 輸入 c:\junk\
- Optional Start number -- 輸入 2(表示從二因子模式開始選)
- Optional stop number -- 輸入 5(表示模式內最多五因子)
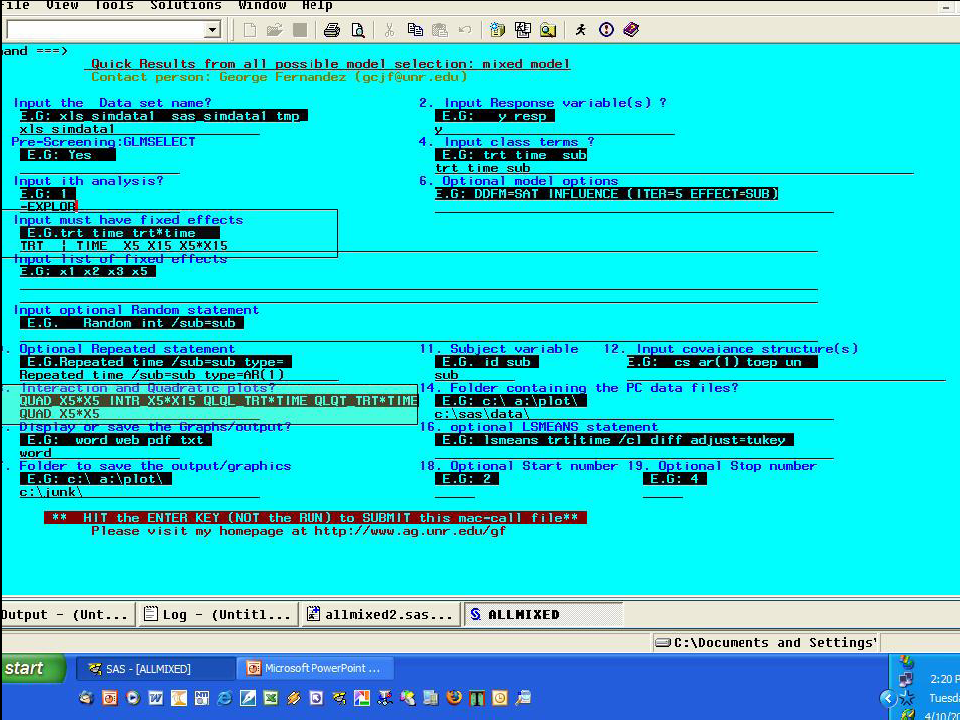
步驟四是在進行一些探索性統計圖表的繪製。
- Input the Data set name? -- 輸入 xls_simdata2
- Input Response variable(s)? -- 輸入 y
- Pre-Screening: GLMSELECT -- 本階段不需要,所以空白
- Input class terms? -- 輸入 trt time sub
- Input ith analysis? -- 輸入 -EXPLOR
- Optional model options -- 本階段不需要,所以空白
- Input must have fixed effects -- 輸入 trt|time x5 x15 x5*x15(這是步驟三找出的最佳模式)
- Input list of fixed effects -- 本階段不需要,所以空白
- Input optional Random statement -- 本階段不需要,所以空白
- Optional Repeated statement -- 輸入 repeated time/sub=sub type=ar(1)
- Subject variable -- 輸入 sub
- Input covariance structure(s) -- 本階段不需要,所以空白
- Interaction and quadratic plots? -- 輸入 quad x5*x5(程式會畫出 x5 的二次項和反應變數的關係圖)
- Folder containing the PC data files -- 輸入 c:\sas\data\
- Display or save the Graphs/output? -- 輸入 word
- optional LSMEANS statement -- 本階段不需要,所以空白
- Folder to save the output/graphics -- 輸入 c:\junk\
- Optional Start number -- 本階段不需要,所以空白
- Optional stop number -- 本階段不需要,所以空白
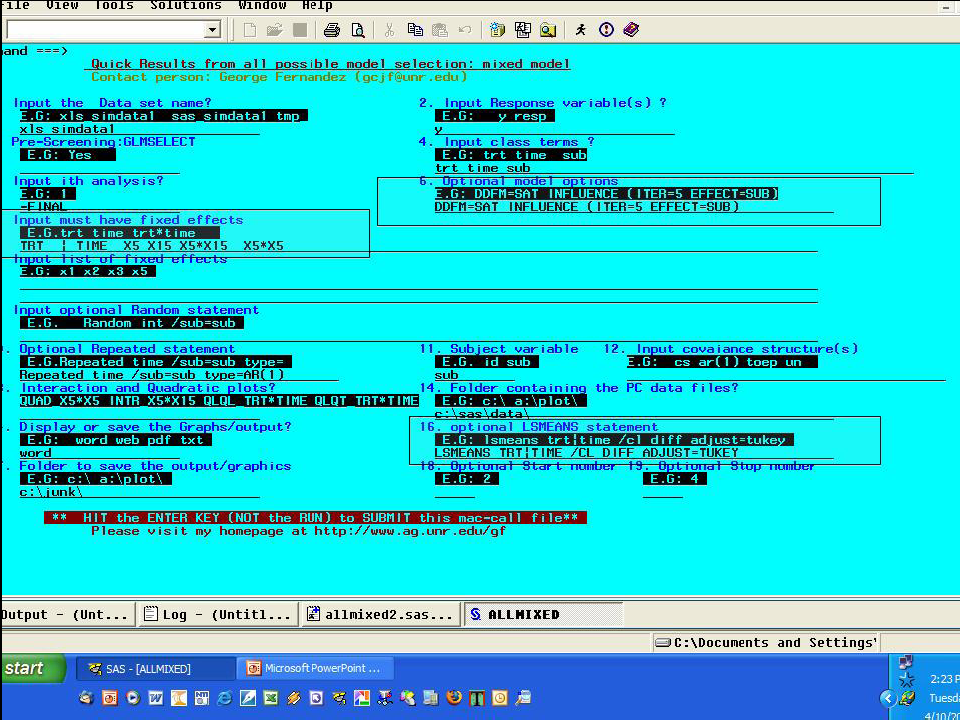
此步驟是在進行模式診斷。
- Input the Data set name? -- 輸入 xls_simdata1
- Input Response variable(s)? -- 輸入 y
- Pre-Screening: GLMSELECT -- 本階段不需要,所以空白
- Input class terms? -- 輸入 trt time sub
- Input ith analysis? -- 輸入 -FINAL
- Optional model options -- 輸入 ddfm=sat influence (iter=5 effect=sib_
- Input must have fixed effects -- 輸入 trt|time x5 x15 x5*x15 x5*x5(步驟四檢定出 x5 的二次項是顯著的,所以在這個步驟加入此二次項)
- Input list of fixed effects -- 本階段不需要,所以空白
- Input optional Random statement -- 本階段不需要,所以空白
- Optional Repeated statement -- 輸入 repeated time/sub=sub type=ar(1)
- Subject variable -- 輸入 sub
- Input covariance structure(s) -- 本階段不需要,所以空白
- Interaction and quadratic plots? -- 本階段不需要,所以空白
- Folder containing the PC data files -- 輸入 c:\sas\data\
- Display or save the Graphs/output? -- 輸入 word
- optional LSMEANS statement -- 輸入 lsmeans trt|time /cl diff adjust=tukey
- Folder to save the output/graphics -- 輸入 c:\junk\
- Optional Start number -- 本階段不需要,所以空白
- Optional stop number -- 本階段不需要,所以空白
CONTACT INFORMATION
Your comments and questions are valued and encouraged. Contact the author:
Name: Dr. George C. Fernandez,
Enterprise: University of Nevada - Reno
Address: CABNR/204 Reno, NV 89557
Work phone: (775)-784-4206
Email: gcjf@unr.edu
Web: Http://www.ag.unr.edu/gf
沒有留言:
張貼留言
要問問題的人請在文章下方的intensedebate欄位留言,請勿使用blogger預設的意見表單。今後用blogger意見表單留言的人我就不回應了。