SAS 強大的資料管理功能大概是無庸置疑的,但困難的語法以及邏輯觀念的需求則是許多普通使用者沒有辦法在短時間內理解的,尤其是在資料轉置或合併的時候。Mike Zdeb 在 2006 年的 NESUG 發表了一篇技術文件,提供多種範本讓大家輕鬆轉置或合併檔案。
轉置:橫變直
假設原始資料是個重複觀測資料,但資料型態卻是每個重複的觀測值自存成一個新的變數,如下所示:
data many_dx;
infile datalines missover;
input id : $2. (dx1-dx5)(:$3.);
datalines;
01 647 641 650 428
02 428 416
03 642 674 648
04 641 416 648 647 641
;
run;要將這類橫向紀錄的資料轉成直向記錄的資料,可以用 PROC TRANSPOSE 輕鬆達成:
proc transpose data=many_dx out=all_dx;
var dx1-dx5;
by id;
run;其中:
- data = 要轉置的檔
- out = 轉置後輸出的檔
- var = 要轉置的變數
- by = 根據哪個變數來依序轉置

如果想要和一般的矩陣轉置一樣,讓行變成列,列變成行,可以用下面的程式來達成:
data many_dx;
infile datalines missover;
input id dx1-dx5;
datalines;
01 647 641 650 428
02 428 416
03 642 674 648
04 641 416 648 647 641
;
run;
proc transpose data=many_dx out=all_dx;
run;則資料會變成:

轉置:直變橫
假設資料型態是每個觀測值有兩個變數,並且重複測量多次,資料輸入程式為:
data deposits;
input account : $2. month deposit @@;
datalines;
01 1 100 01 4 50 01 6 200
02 2 50 02 3 100
03 1 50 03 2 50 03 3 50 03 4 50 03 5 50 03 6 50
;
run;會長的像這個樣子:

我們可用 PROC TRANSPOSE 一次同時轉兩個變數:
proc transpose data=deposits out=acct_deposits;
by account;
run;則資料會轉成這個型態:

如果只要轉 deposit 這個變數,程式如下:
proc transpose data=deposits out=acct_deposits;
var deposit;
by account;
run;資料變成這個的樣子:

如果想要把上面的變數名稱改成 month,首先需先將原始資料中的 month 改成文字型態:
data deposits;
input account : $2. month : $3. deposit @@;
datalines;
01 JAN 100 01 APR 50 01 JUN 200
02 FEB 50 02 MAR 100
03 JAN 50 03 FEB 50 03 MAR 50 03 APR 50 03 MAY 50 03 JUN 50
;
run;
在 PROC TRANSPOSE 中,用 id
proc transpose data=deposits out=acct_deposits (drop=_name_);
var deposit;
by account;
id month;
run;從下圖可見 month 的紀錄都變成了轉置後的變數名稱:

其他轉置方法
高階使用者可能不屑用 PROC TRANSPOSE 這個簡單的玩意兒,而是直接在 data step 的階段進行轉置。以第一個例子來說,可以用下面的程式來完成:
data all_dx;
set many_dx;
array dx(5);
do j=1 to 5;
diag=dx(j);
if diag ne ' ' then output;
end;
keep diag;
run;若是第二個例子,則程式比較複雜:
data all_dx;
retain dep1-dep6;
set deposits;
by account;
array dep(6);
if first.account then do j=1 to 6;
dep(j) = .;
end;
dep(month) = deposit;
if last.account then output;
keep account dep1-dep6;
run;其實簡單來說,都是在玩弄陣列(array)的技巧。但我仍推薦 PROC TRANSPOSE 來轉置資料。用 data step 來玩轉置的唯一好處是可以同時進行其他變數變換的動作,而 PROC TRANSPOSE 就只是單純在做變數轉置而已。
合併資料
接下來用兩筆資料來討論一些合併資料的程式:

data jan;
input ssn weight zip : $5.;
format ssn ssn.;
datalines;
001001234 180 12203 i
123456789 150 13502
888888888 200 14001
987654321 120 12345
;
run;
data feb;
input ssn weight;
format ssn ssn.;
datalines;
001001234 160 i
123456789 145
987654321 125
999999999 150
;
run;最簡單的合併,就是跟去 snn 將 weight 和 zip 合併起來:
data jan_feb;
merge jan feb;
by ssn;
run;合併後的資料:

data jan_feb;
merge jan (rename=(weight=wt1)) feb (rename=(weight=wt2));
by ssn;
diff = wt2 - wt1;
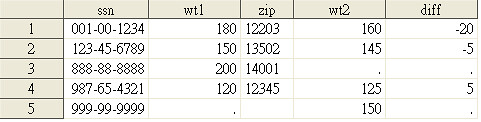
run;上面的程式就是在合併的過程中將資料 Jan 的 weight 改名為 wt1,資料 Feb 的 weight 改名為 wt2。接著,令兩者相減,造出一個新的變數名為 diff。結果如下所示:
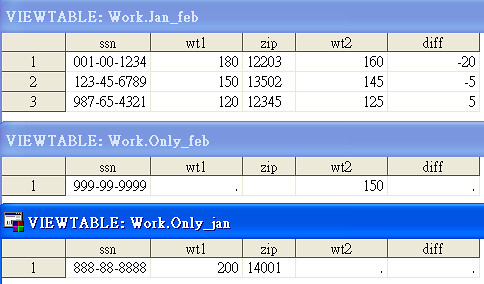
data jan_feb only_jan only_feb;
merge jan (in=j rename=(weight=wt1))
feb (in=f rename=(weight=wt2));
by ssn;
diff = wt2 - wt1;
if j and f then output jan_feb;
else if j then output only_jan;
else output only_feb;
run;這裡用到一個特殊技巧就是「in=」的應用。他會製造一個隱形的變數(如範例中的 j 和 f),當觀測值或變數是在資料 Jan 時,則 j=1,反之 j=0。同理,當觀測值或變數是在資料 Feb 時,則 f=1,反之則 f=0。程式中利用 if ... then ... else ... 的語法,讓 j=k=1 的觀測值存入新資料 jan_feb 中,如果只有 j=1 則存入 only_jan 中,如果只有 k=1 則存入 only_feb 中。因此,一個 data step 可以一次產生三個檔案:
merge 語法經常出現一個問題。如果兩個資料的觀測值都是一對一,那合併起來自然沒啥問題,但如果某個觀測值在兩個資料裡面的個數是不等的,如下所示:
data demographic;
input name : $5. age zip : $5.;
datalines;
ADAMS 20 12203
BROWN 21 10001
SMITH 50 12005
SMITH 33 12012
;
run;
data medical;
input name : $5. age hr chol ;
label
hr = 'heart rate'
chol = 'cholesterol'
;
datalines;
ADAMS 20 89 200
BROWN 21 60 140
SMITH 34 71 150
;
run;
則合併起來會出現很詭異的情況:
data both;
merge demographic medical;
by name;
run;
上圖中,有沒有發現,當名字是 SMITH 時,age=50的那筆資料被 age=34 蓋掉了。Mike Zdeb 在文內並沒有提到解決的方法,只有提醒使用者注意。如果不想讓第一個資料檔裡面的觀測值被第二個資料檔裡面的觀測值覆蓋的話,可以用下面的程式解決:
proc sort data=demographic; by name age; run;
proc sort data=medical; by name age; run;
data both;
merge demographic medical;
by name age;
run;這個道理就是讓 name 和 age 兩個變數都丟入 merge 合併的依據準則內,這樣一來兩個變數就不會產生覆蓋的情況。不過要 merge 前一定要先對這兩個變數做 PROC SORT。執行程式後會得到:

其他還有一些進階使用 RPOC SQL 的語法,熟悉 PROC SQL 的人可以詳讀原文。在此不做敘述。
CONTACT INFORMATION
The author can be contacted using e-mail... msz03@albany.edu
沒有留言:
張貼留言
要問問題的人請在文章下方的intensedebate欄位留言,請勿使用blogger預設的意見表單。今後用blogger意見表單留言的人我就不回應了。