在 merge 不同的資料集之前,如果有些變數名稱相同時會導致 merge 失敗。處理這種問題的方法不外乎是先把重複的變數名稱重新命名。rename 是 SAS data step 裡面用來重新替變數命名的基本語法,可是一旦重複的變數太多,用 rename 一個個輸入新變數名稱就會變的冗長耗時。Christopher J. Bost 在 NESUG 2007 提供了一種用 PROC SQL 快速大量自動重新命名的方法,在此提供給大家一個參考。
簡單地來看一個例子。假設下面兩個資料集準備要拿來合併:

在這兩個不同的資料集裡面,變數 b 和 c 具有重複的變數名稱。因此在使用 merge 合併時,我們通常都會用下面這段程式碼替其中一邊的 b 和 c 重新命名:
data onetwo;
merge one two(rename=(b=TWOb C=TWOC));
by id;
run;結果如下:

可是,如果有幾十個,甚至幾百個變數都需要 rename 的話,那就必須得一一輸入 oldname = newname 這段程序。雖然在技術上不是什麼太大的問題,只要你有時間,一定是可以慢慢輸入完的。不過如果有更快速的方法能夠把 rename 這個動作用極短的程式碼來完成,而且還不需要另外呼叫其他 macro 來處理的話,那就更好了。
PROC SQL 程序可以取得一些 SAS 內部的訊息。這些訊息當然不是擺著好看的,可是懂得利用這些訊息的人並不多。所有變數和資料集的訊息,都會放在一個叫做 DICTIONARY.COLUMNS 的物件裡面。想要知道裡面有什麼訊息,可以用這段程式碼呼叫出來:
proc sql;
describe table dictionary.columns;
quit;結果不是在 output,而是在 log 視窗裡面:
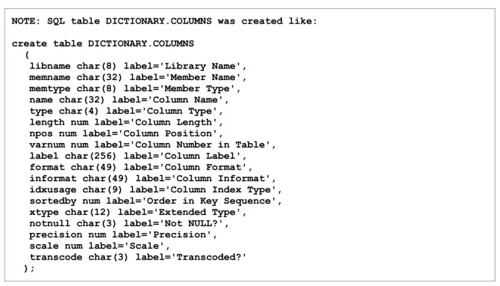
其中有三個訊息是可以拿來做重新命名的,分別是 libname、memname 和 name。如果想要知道這三個東西的詳細資訊,則可以用下面這段程式碼叫出:
proc sql;
select libname, memname, name
from dictionary.columns
where libname='WORK' and memname='ONE';
quit;結果如下:

這段程式碼把資料集 one 和所在的 libary、資料集檔名以及內部變數名稱都列舉出來。特別注意一點是,library 和 memname 裡面的資訊都一概大寫,所以在 where statement 後面的 libname= 和 memname= 都要接上大寫的 library name 和 data set name,即便是這些原先都是小寫,還是得改成全部大寫。
如果只想知道變數訊息,則程式碼得改成:
select upcase(name)
from dictionary.columns
where libname='WORK' and memname='ONE' and upcase(name) ne 'ID';由於 name 裡面的變數名稱大小寫會符合原始資料裡面的設定,但是 PROC SQL 在這部分只認得大寫,所以必須使用 upcase(name) 把裡面的資訊全部變成大寫,然後再把小寫的 id 變成大寫的 ID。如果單獨用 PROC SQL 跑這段程式,輸出結果如下所示:

接著,針對資料集 two,我們也只想知道其變數資訊,則可用下面這段程式碼:
select name
from dictionary.columns
where libname='WORK' and memname='TWO' and upcase(name) in ( previous query )其中 previous query 上指上一段叫出資料集 one 變數訊息的程式碼。如果單獨跑這段程式,輸出結果如下所示:

最後,重新命名的動作就交給下面這段程式碼:
select trim(name) || '=' || 'TWO' || name
from ( previous query )這邊的 previous query 則是繼續把前兩段程式碼給複製進來。trim() 函示是把可能的空白給去掉。這個 select statement 會產生下面這種結果:

這個結果不就是 rename statement 後面要輸入的 oldname=newname 嗎?為了要把這段結果放進 data step 來自動重新命名,需要再多一行程式:
into :renamelist separated by ' '這行程式會把之前所有 oldname=newname 的結果放在 renamelist 這個巨集參數裡面,並且每一段都用一個空格區分開來(這就是 separated by ' ' 的目的)。結合上面的程式:
proc sql noprint;
select trim(name) || '=' || 'TWO' || name
into :renamelist separated by ' ' from
(select name
from dictionary.columns
where libname='WORK' and memname='TWO' and upcase(name) in
(select upcase(name)
from dictionary.columns
where libname='WORK' and memname='ONE' and upcase(name) ne 'ID'));
quit;這段程式碼混在一起就會把「b=TWOb c=TWOc」這段程式碼放進 renamelist 裡面。雖然他看起來很複雜,但根據不同的情況只需要改兩個地方即可:
1. 第一個 select statement 後面的 TWO 可以改成自己想要重新命名的變數名稱開頭。
2. 最後一個 where statement 後面的 ID 改成你自己要合併資料集所使用的合併準則。此例是 merge by id,所以這邊就要用 ID。如果你是 merge by subject,則此處就改成 SUBJECT。
然後使用下面這段程式碼把 renamelist 設定成巨集變數:
%put &renamelist;最後只要在一開始的 data step 裡面做點小更改即可:
data onetwo;
merge one two(rename=(&renamelist));
by id;
run;只要把 rename 後面可能的一長串 oldname=newname 換成 &renamelist 就大功告成了。結果如下所示:
當然,如果你覺得之前介紹的 text utility 裡面的 rename macro 很好用的話也可以使用他。
CONTACT INFORMATION
Christopher J. Bost
Director, Research Technology Unit
MDRC
16 East 34th Street, 19th Floor
New York, NY 10016
(212) 340-8613 telephone
(212) 684-0832 fax
christopher.bost@mdrc.org
www.mdrc.org
沒有留言:
張貼留言
要問問題的人請在文章下方的intensedebate欄位留言,請勿使用blogger預設的意見表單。今後用blogger意見表單留言的人我就不回應了。