最近因為在處理一批很複雜的模擬結果時遇到不知名的原因所產生的重複資料(duplicated data)。由於手動刪除相當麻煩,所以得依賴 SAS 的程式判斷可能的重複資料,並把多餘的給予 刪除。Wendi Wright 在 2007 年的 SUGI 31 上發表了一篇關於處理重複資料的程序,實用性十足,語法也相當簡單。
首先,在單一資料中,尤其是數據很多時,如何來做重複資料初步的檢驗,得知重複資料是否存在的訊息。這到手續可以簡單的用 PROC FREQ 和 PROC PRINT 來完成。
PROC FREQ;
TABLES keyvar / noprint out=keylist;
RUN;
PROC PRINT;
WHERE count ge 2;
RUN;上例中,只檢查 keyvar 這個變數是否有重複值,並把 PROC FREQ 的結果存成 keylist 這個新的資料集。然後用 PROC PRINT 來印出 keylist 的內容。由於 SAS 在生成 keylist 時會自動把每個值出現的次數算好並存在一個新變數 count 裡面,所以只要在 PROC PRINT 後面加上一個 where statement 並把 count 設定成大於等於二即可。
如果有好幾個變數,則只要把上面的範例稍微改一下即可:
PROC FREQ;
TABLES keyvar1*keyvar2*keyvar3*keyvar4 / noprint out=keylist;
RUN;
PROC PRINT;
WHERE count ge 2;
RUN;附帶說明一點,我個人的習慣是喜歡在 PROC PRINT 後面加上 data= 以指定要列印哪個資料集。原文的範例程式雖然沒有使用,但強烈建議使用者能夠養成這個習慣。
值得注意的是,如果每個變數都是連續變數,而非單純的離散變數,則經過各變數組合後的 PROC FREQ 報表會相當長,也容易出現這個錯誤訊息(但不會影響輸出結果):
ERROR: Unable to allocate sufficient memory. At least 1168978K bytes were requested. You must either increase the amount of memory available, or approach the problem differently.Wright 所提出的解決方法是用另一個 data step 把變數先合併起來,如下所示:
DATA ---;
…other statements …;
LENGTH keyvar $50;
Keyvar = keyvar1 || put(keyvar2,3.) || keyvar3 || keyvar4;
… other statements…;
RUN;使用「||」符號把四個變數的值給黏起來,但如果有一個變數的屬性和其他變數不同,我們可以用 put 指令做變數屬性轉換。此外,此例的 keyvar 長度只設定為 50,使用者應該是情況增長或縮短該變數長度。
其次,如果真的有重複值出現,而且只需要保留其中一個的話,那就需要用別的語法來剔除不需要的重複變數。引用原文的例子:
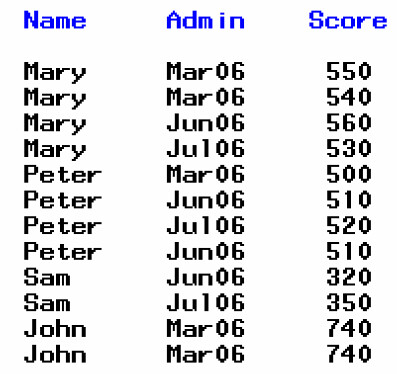
這個資料裡面,Mary 和 Peter 重複四次,Sam 和 John 重複兩次,其中 Mary 在 Admin 中重複兩次(Mar06),Peter 也是(Jun06),而且 Peter 重複的兩次是連 Score 也跟著重複。同樣的情況也發生在 John 的資料上面。
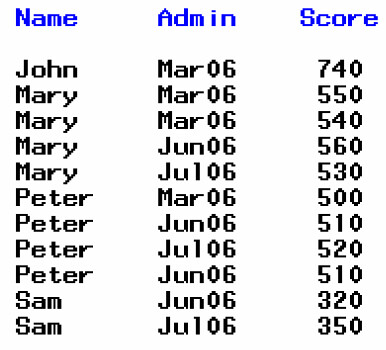
想要刪除重複值,可以使用 PROC SORT 加上一個 NODUP 的 option 就可以完成:
PROC SORT data=sample NODUP;
BY name;
RUN;結果如下:
PROC SORT data=sample NODUP;
BY _all_;
RUN;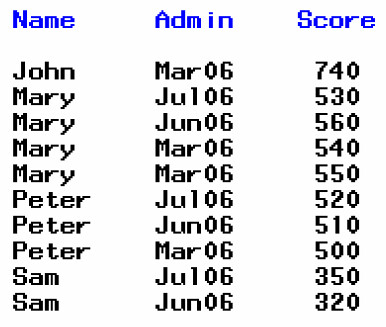
特別警告一點,那就是 PROC SORT 在大型資料集裡面的運作相當消耗時間,再加上比對重複值和剔除的動作,可能會耗上個幾十分鐘也不為過,所以若你發現執行後電腦沒有立刻有所反應,請去泡杯咖啡耐心等待先。
如果要進行條件限制更嚴格的重複值剔除,也就是說只有有任何一個變數具有重複值就剔除,那就必須使用 NODUPKEY 這個 option 來完成:
PROC SORT data=sample NODUPKEY;
BY name;
RUN;NODUPKEY 會從資料裡面第一個變數開始做刪除重複值的動作,一個接著一個,直到排序完最後的變數為止。所以從結果可以看出,每個 subject 都只剩下一筆資料了。

PROC SORT data=sample;
BY id descending score;
RUN;
PROC SORT data=sample nodupkey;
BY id;
RUN;結果如下:

NODUPKEY 和 BY statement 裡面的 descending 不能放在一起,所以要分開執行。由於第一次 PROC SORT 已經把所有的資料都排列好了,所以第二個 PROC SORT 很快就可以把剔除重複值的動作完成,不會浪費太多時間(不過第一個 PROC SORT 還是會很耗時)。
AUTHOR CONTACT
Wendi L. Wright
1351 Fishing Creek Valley Rd.
Harrisburg, PA 17109
Phone: (717) 513-0027
E-mail: sleepypuppyfeet@earthlink.net
沒有留言:
張貼留言
要問問題的人請在文章下方的intensedebate欄位留言,請勿使用blogger預設的意見表單。今後用blogger意見表單留言的人我就不回應了。