許多統計方法在進行時,多半會把 missing data 完全移除。好處是處理方便,壞處是,有時missing data 仍有一些有用但未知的資訊,我們永遠也不知道刪除他們會產生什麼重大的影響。另一方面,有時 missing data 太多,導致樣本變很小,power 一整個降低。在 SAS 中,PROC MI 和 PROC MIANALYZE 這兩個程序可以用一些內插法來補 missing data,以降低刪除 missing data 對資料本身的傷害性。不過 David Lanning 和 Doug Berry 利用更簡單的方法來做到內插的效果,並將結果發表於 2003 年的 SUGI 28 上。
簡單來說,David Lanning 和 Doug Berry 是用 PROC MEANS 程序來抓出每個變數的最小值和全距(同時間最大值也被決定了),並進行資料插補的動作,使的新增資料會在這個全距中隨機生成,並讓新的變數平均數和舊的變數平均數不會差異太多,減低填補的資料可能會造成資料巨大變異的可能性。
David 和 Doug 只有在文內發表他們所寫的程式,而沒有詳細解釋。我試著來解譯每個部分的功能。
資料如下:
data one;
input abbrid $ cnt amt_rnd amt_dec age @@;
datalines;
DTL 1 110 30.67 21 KRL 2 320 24.56 22
ARL 3 330 . 23 GLM . . . .
CRM 5 150 45.32 . MGM 6 . 28.12 26
PRG . 270 . 27 RDS . . 34.00 .
JKS 9 . . . DTL 2 160 54.98 20
KRL 4 180 67.54 22 ARL 6 140 34.13 24
GLM . . . . CRM 8 170 23.87 .
MGM 2 . 43.76 26 PRG . 130 12.54 28
RDS . . . . JKS 5 . . .
DTL 3 190 43.67 23 KRL 7 110 32.87 26
ARL 3 120 34.34 29 GLM . . . .
CRM 5 130 54.12 . MGM 2 . 76.43 21
PRG . 140 19.92 25 RDS . . . .
JKS 8 . 53.13 . JTS 6 . 73.93 30
;
run;利用 PROC MEANS 來計算每個數值變數的最小值和全距,並存成新的資料集 three。
proc means data=one noprint;
var _numeric_;
output out=three (drop=_freq_ _type_) min= range= / autoname;
run;製造一個暫時的資料集 _null_(不會顯示在library內),並把資料集 three 引入。裡面有個 symput 指令,可以將 data step 中的變數轉成 macro 可用的變數。我會在之後的文章引用另一篇 SUGI 的文章來討論 symput。但簡單來講,這個資料集將剛剛用 PROC MEANS 生出的資料集 three 中的所有結果存成新的變數以讓之後的程序可以直接用到。
data _null_;
set three;
array ass{*} _numeric_;
do i=1 to dim(ass);
call symput(vname(ass(i)),ass(i));
end;
drop i;
run;新增一個資料集 four,並引入舊資料集 one。這一個步驟最主要就是在計算插補到 missing data 的數據。增補的根據是用 Uniform 分配生出亂數,並乘上之前算出來的全距,最後再加上最小值(粗體字部分)。
data four;
set one;
array wit{*} _numeric_;
do i=1 to dim(wit);
if wit(i)=. then
wit(i)=round((ranuni(0)*(symget(vname(wit(i))||'_range')))+(symget(vname(wit(i))||'_min')));
end;
drop i;
run;現在我們來比較新舊資料集的結果。
[舊資料]
proc means data=one min max range mean;
title 'Original dataset with missing values';
run;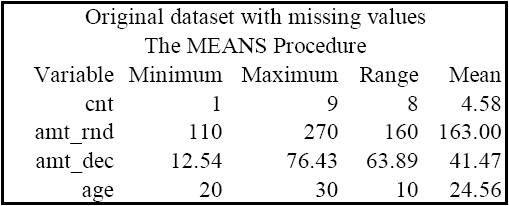
[新資料]
proc means data=four min max range mean;
title 'New dataset using random generated values for missing observations';
run;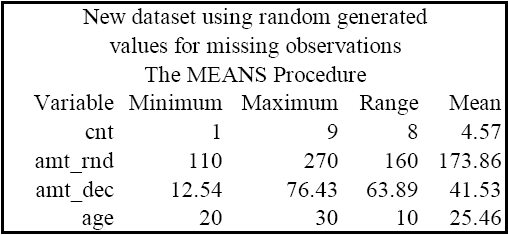
由上面兩張圖表可知,新舊資料集的 Min, Max 和 Range 完全一樣,只有 Mean 的部分有些微不同。這種方法並沒有牽涉到太複雜的統計模擬運算,純粹是要解決 PROC MI 在插補龐大資料時所可能會消耗的冗長時間。由於兩人是在知名的保險公司 State Farm 工作,可想而知龐大的客戶群資料也許沒有辦法讓他們慢慢等待 PROC MI 模擬生成的效果。
CONTACT INFORMATION
Your comments and questions are valued and encouraged.
Contact the author at:
David Lanning
State Farm Insurance Companies
One State Farm Plaza – SC-3
Bloomington, IL 61710-001
Work Phone: (309)735-2723
Email: david.lanning.lyus@statefarm.com
沒有留言:
張貼留言
要問問題的人請在文章下方的intensedebate欄位留言,請勿使用blogger預設的意見表單。今後用blogger意見表單留言的人我就不回應了。